配置文件
简介
云原生构建配置文件定义代码仓库在特定事件(如推送新 Commit、创建 Pull Request)触发时执行的构建任务及各步骤操作。
配置文件说明
配置文件规范
- 文件名为
.cnb.yml,存放于代码仓库根目录,遵循「配置即代码」原则。 - 配置变更可通过 Pull Request 流程管理,适合开源协作。
- 构建流程与源代码同步版本控制,确保透明度和变更可追溯。
- 文件名为
YAML 格式优势
- 支持嵌套结构和键值对,清晰表达复杂配置。
- 易于扩展和修改,适应动态需求,支持注释提升协作效率。
示例配置
以下是一个云原生构建配置示例:
main:
push:
- docker:
image: node:22
stages:
- name: install
script: npm install
- name: test
script: npm test示例流程说明
- 触发条件:当
main分支收到push事件(即有新 Commit 推送至main分支)时,触发构建任务。 - 执行环境:使用
node:22Docker 镜像作为任务执行环境。 - 任务步骤:
- 执行
npm install安装依赖。 - 执行
npm test运行测试。
- 执行
基本语法结构
配置文件的基本结构如下所示:
main:
push:
- name: push-pipeline1
stages:
- script: echo 1
- name: push-pipeline2
stages:
- script: echo 2一个事件下可包含多条 pipeline,支持数组(推荐)和对象两种写法, 多条 pipeline 会并发执行。其中:
main表示分支名称push、pull_request表示触发事件- 一条 pipeline 包含一组顺序执行的
stages,在同一个构建环境中运行
更详细的语法说明参阅:语法手册
配置文件版本选择
配置文件版本的选择规则与代码版本选择相同。
语法检查和自动补全
VSCode
推荐使用 云原生开发 环境编写配置文件,其原生支持语法检查和自动补全,效果如下:
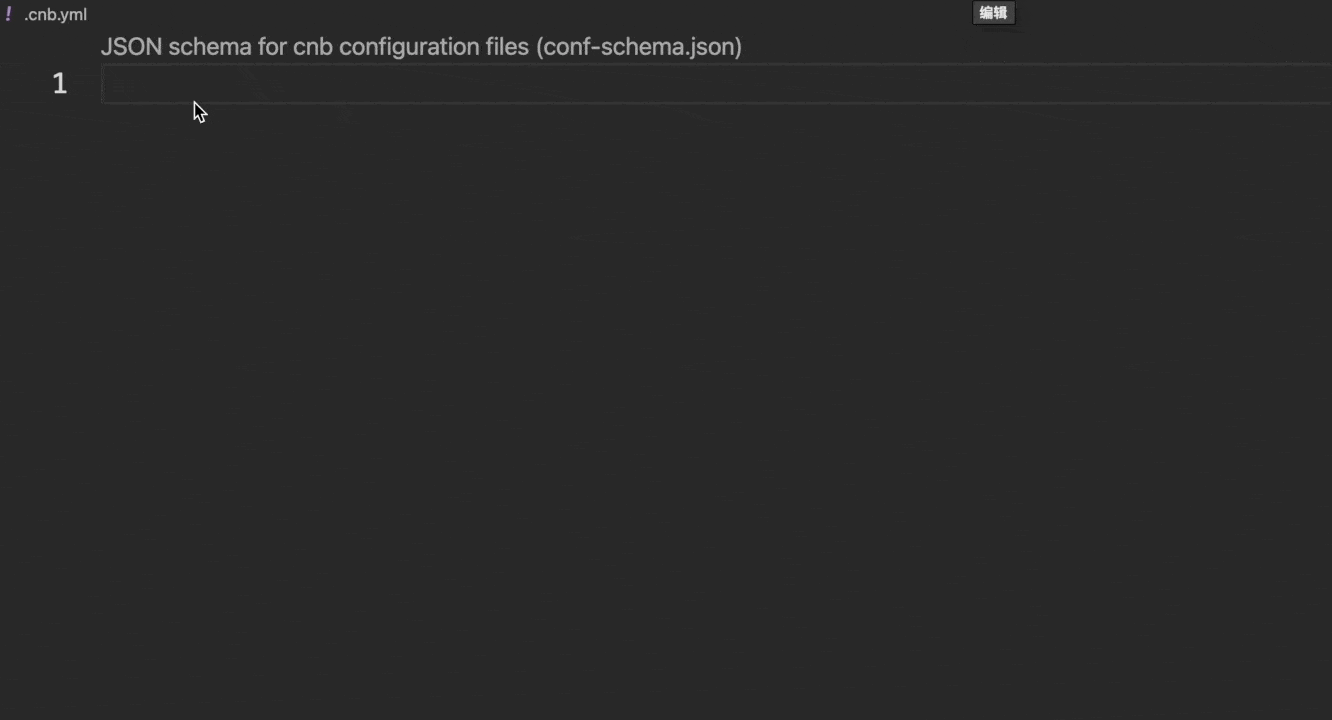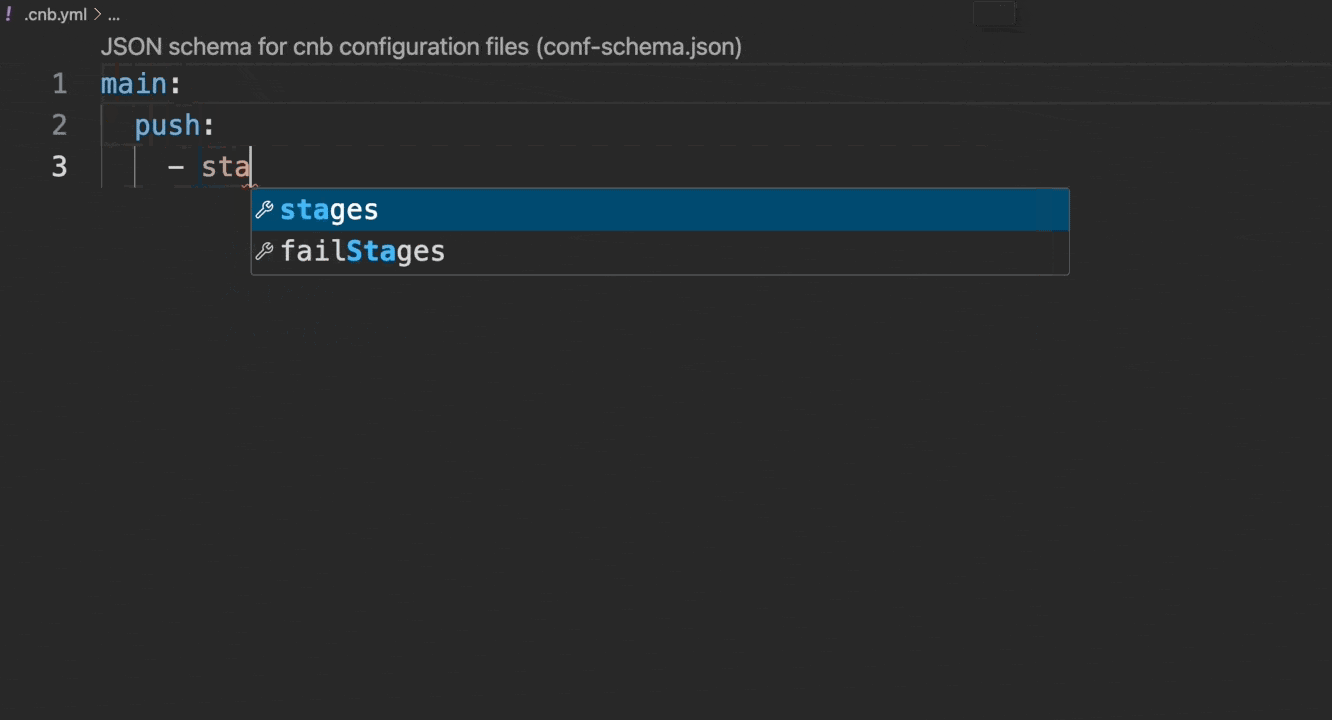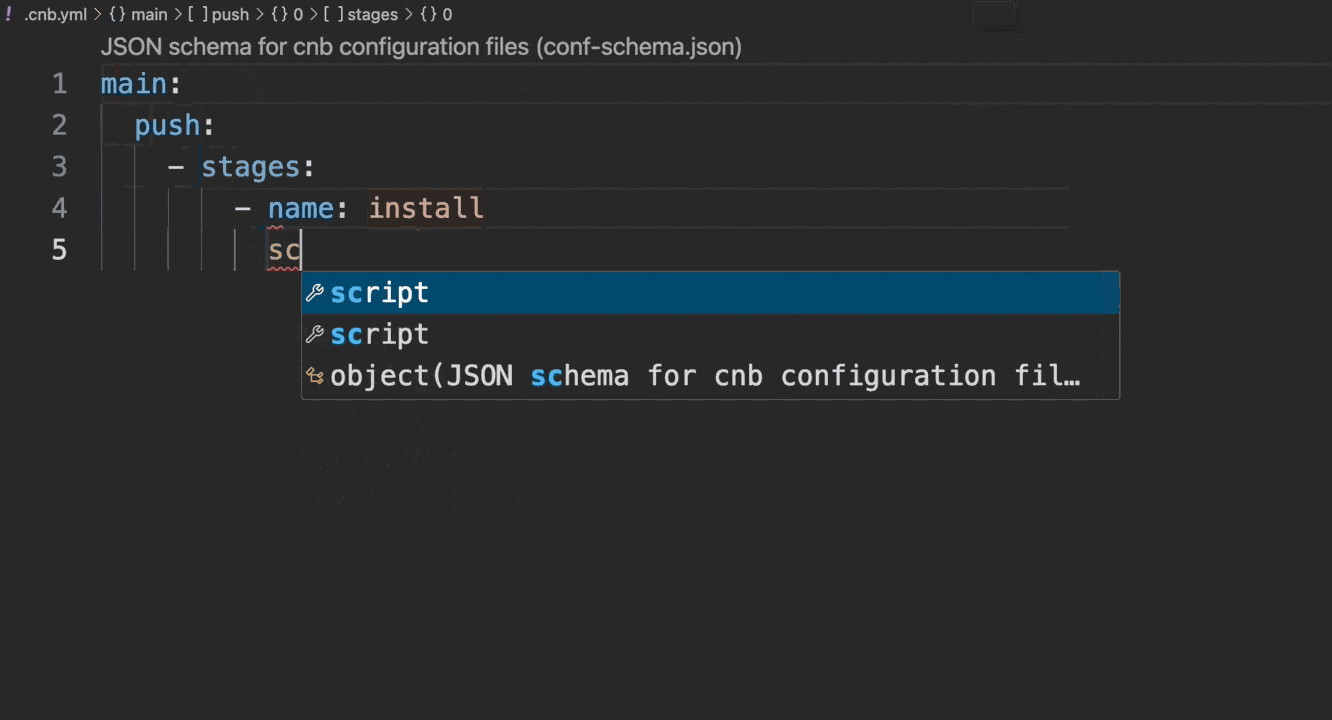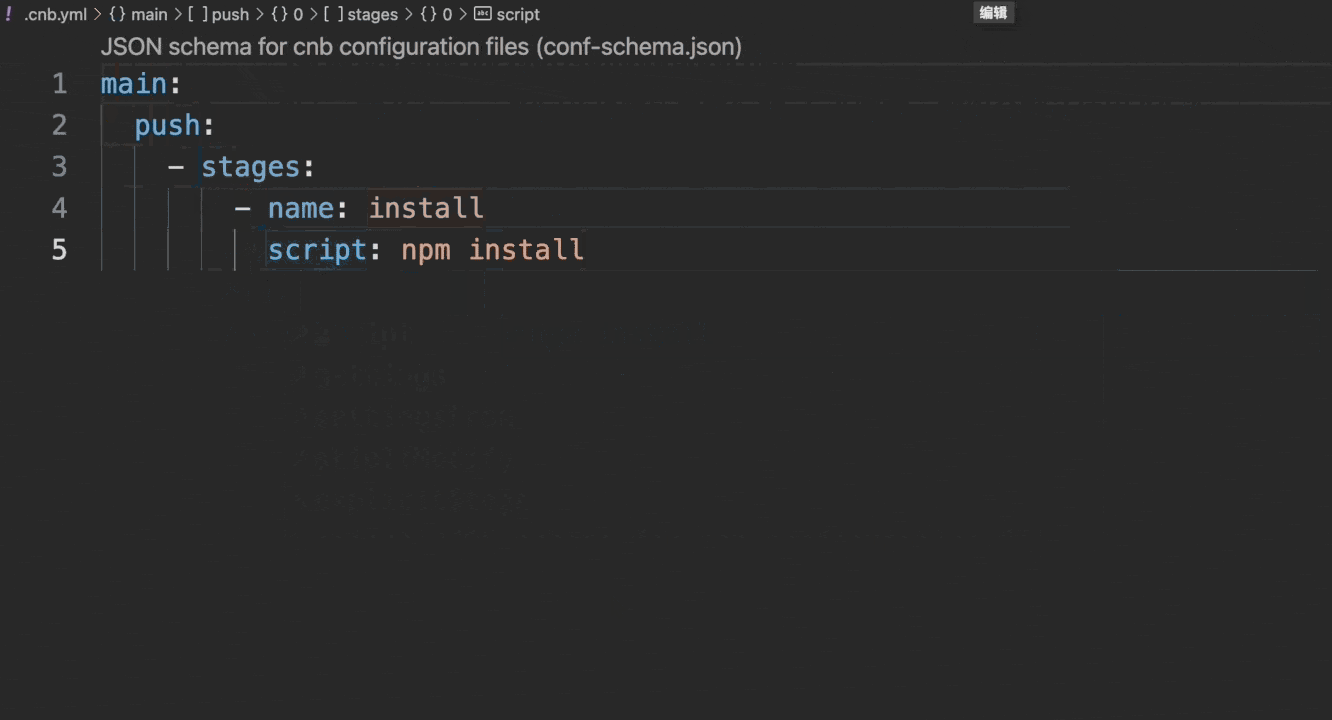
若在本地 VSCode 中开发,可按以下步骤配置:
安装
redhat.vscode-yaml插件。在
settings.json配置文件中加入以下内容:{ "yaml.schemas": { "https://docs.cnb.build/conf-schema-zh.json": ".cnb.yml", "https://docs.cnb.build/tag-deploy-schema-zh.json": ".cnb/tag_deploy.yml", "https://docs.cnb.build/web-trigger-schema-zh.json": ".cnb/web_trigger.yml", "https://docs.cnb.build/settings-schema-zh.json": ".cnb/settings.yml", "https://docs.cnb.build/code-security-conf-schema-zh.json": ".cnb/security/code_scan_config.yml" } }
JetBrains
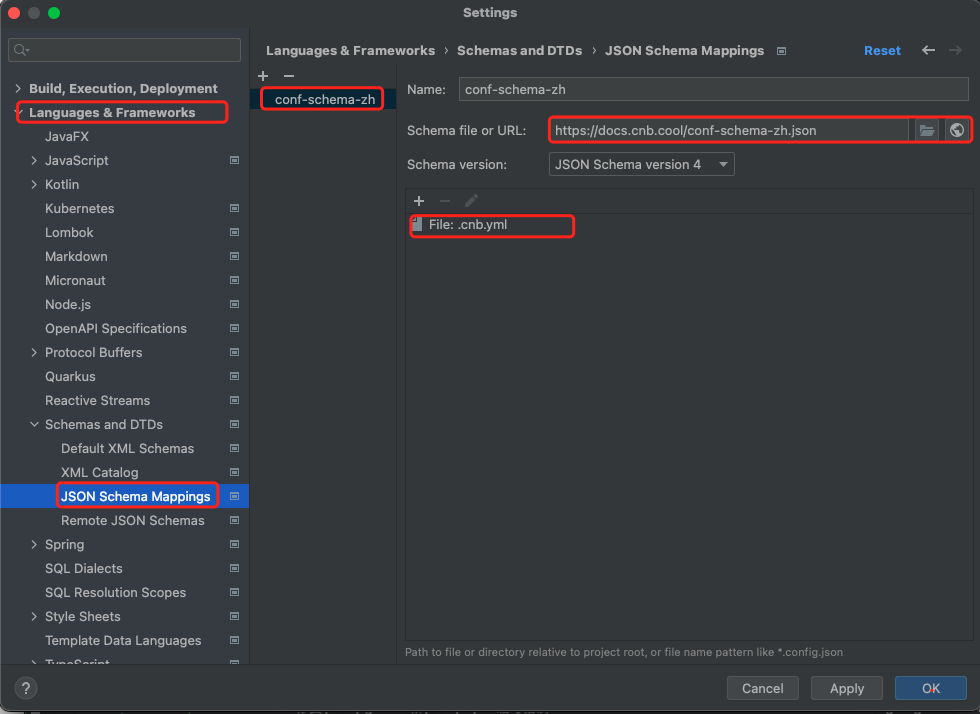
- 打开
Settings/Preferences。 - 进入
Languages & Frameworks->Schemas and DTDs->JSON Schema Mappings。 - 点击
+添加新的映射,共添加五条:https://docs.cnb.build/conf-schema-zh.json→.cnb.ymlhttps://docs.cnb.build/tag-deploy-schema-zh.json→.cnb/tag_deploy.ymlhttps://docs.cnb.build/web-trigger-schema-zh.json→.cnb/web_trigger.ymlhttps://docs.cnb.build/settings-schema-zh.json→.cnb/settings.ymlhttps://docs.cnb.build/code-security-conf-schema-zh.json→.cnb/security/code_scan_config.yml